How to run solvers
What’s a solver?
In this context, a solver is an entity which takes an initial field together with problem-specific parameters, then performs a numerical simulation and either provides on-the-fly output or just final results. Solvers are assembled in a modular fashion as will be illustrated below. The chosen timestepper and ODE class can be just-in-time compiled based on the given VoxelGrid backend.
Example: Cahn-Hilliard equation
For the context of this little example we will focus on the periodic two-phase Cahn-Hilliard equation which can be shortly summarized as follows: We start from a free energy functional for a two-phase system
where \(\gamma_0\) [J/\(\text{m}^2\)] denotes the interfacial energy and \(\epsilon\) [m] scales the width of the diffuse interface. Note that in this case, the homogeneous free energy is given by a double-well potential while in the context of the Cahn-Hilliard equation a regular solution free energy involving logarithmic terms is often employed (see original work of Cahn & Hilliard). However, the following procedure would be identical in all cases.
The second order phase transition problem - also known as the Cahn-Hilliard equation - can be derived by inserting the chemical potential \(\mu=\delta f_\text{int}/\delta\phi\) given by the functional derivative of the given free energy formulation into the mass conservation equation which yields
which is a fourth-order PDE in space. Specifically, we use a variable mobility of the form \(M=D_0 \phi(1-\phi)\) and the homogenous part of the chemical potential is given by the polynomial expression \(g(\phi)=\frac{18}{\epsilon}\phi(1-\phi)(1-2\phi)\) which is derived from the double-well potential in the energy functional.
Execute the precompiled solver
We start by creating a VoxelFields object which is large enough to compare computation times. Random noise is used as the inital condition of the concentration field.
[1]:
import evoxels as evo
import numpy as np
Nx, Ny, Nz = [150, 150, 150]
vf = evo.VoxelFields((Nx, Ny, Nz), domain_size=(Nx, Ny, Nz))
noise = 0.5 + 0.1*(0.5-np.random.rand(Nx, Ny, Nz))
noise[0,:,:] = 0.1
evoxels comes with precompiled solvers which can be used out of the box. One such solver is the run_cahn_hilliard_solver() which takes input arguments defining
the numerical backend
timestepping options
problem-specific parameters
output options
[2]:
vf.add_field("c1", noise)
final_time = 1000
dt = 1
steps = int(final_time/dt)
evo.run_cahn_hilliard_solver(
vf, 'c1', 'torch', jit=False, device='cuda',
time_increment=dt, frames=10, max_iters=steps,
eps = 3.0, diffusivity = 1.0,
verbose='plot', vtk_out=False, plot_bounds=(0,1)
)
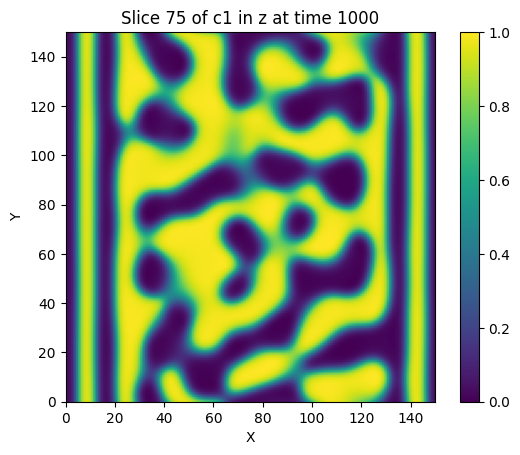
Wall time: 22.5367 s after 1000 iterations (0.0225 s/iter)
GPU-RAM (nvidia-smi) current: 365 MB (365.0 MB max)
GPU-RAM (torch) current: 25.92 MB (148.55 MB max, 176.00 MB reserved)
Assembling custom solvers
We can unwrap what is actually happening under the hood a bit more by manually assembling this solver based on the predefined problem definition, timestepper and solver framework. The TimeDependentSolver is a pre-defined class which initialises a scalar field and solves a time-dependent PDE (as opposed to a steady-state problem). This is done by combining a backend (torch/jax) with a timestepper class (e.g. PseudoSpectralIMEX) and a problem class which defines the numerical
discretisation of the right-hand side of a PDE (e.g. CahnHilliard).
[3]:
from evoxels.problem_definition import CahnHilliard
from evoxels.solvers import TimeDependentSolver
from evoxels.timesteppers import PseudoSpectralIMEX
# Add the same noise as a new field to the VoxelFields
# as c1 has been over-written by the previous solve call
vf.add_field("c2", noise)
solver = TimeDependentSolver(
vf, # VoxelFields object
'c2', # Name of initial field
'torch', # Backend
problem_cls = CahnHilliard, # Problem definition
timestepper_cls = PseudoSpectralIMEX, # Timestepping scheme
device='cuda',
)
solver.solve(
time_increment=dt,
frames=10,
max_iters=steps,
problem_kwargs={"eps": 3.0, "D": 1.0},
jit=False,
verbose=True,
vtk_out=False,
plot_bounds=(0,1),
)
Wall time: 18.4009 s after 1000 iterations (0.0184 s/iter)
GPU-RAM (nvidia-smi) current: 389 MB (389.0 MB max)
GPU-RAM (torch) current: 46.88 MB (155.94 MB max, 168.00 MB reserved)
This yield the exact same outcome as we can see from the voxel-wise difference between the two solution fields
[4]:
print(f"Maximal deviation: {np.max(np.abs(vf.fields['c1']-vf.fields['c2']))}")
Maximal deviation: 0.0
Just-in-time compilation and wall time
So far, the just-in-time compilation has been turned off (jit=False) which means no code optimisation is done. Now, we set jit=True such that the timestepper and rhs definition will be compiled into one GPU kernel. This has two effects
The simulation is significantly faster when jit compiled
The field values deviate as the jit compiled kernel optimizes the order of additions, multiplications, etc.
The average of all absolute per-voxel deviations are still small but larger than float32 single precision (~7 significant decimal digits).
[5]:
vf.add_field("c3", noise)
solver = TimeDependentSolver(
vf, 'c3', 'torch', device='cuda',
problem_cls = CahnHilliard,
timestepper_cls = PseudoSpectralIMEX
)
solver.solve(
time_increment=dt, frames=10, max_iters=steps,
problem_kwargs={"eps": 3.0, "D": 1.0},
jit=True
)
Wall time: 11.1747 s after 1000 iterations (0.0112 s/iter)
GPU-RAM (nvidia-smi) current: 413 MB (413.0 MB max)
GPU-RAM (torch) current: 48.05 MB (144.26 MB max, 182.00 MB reserved)
[6]:
print(f"Mean deviation: {np.mean(np.abs(vf.fields['c2']-vf.fields['c3']))}")
Mean deviation: 7.104756605258444e-06
Instead of the PseudoSpectralIMEX timestepping scheme - aka semi-implicit Fourier spectral method - we could use the simple forward Euler discretisation (ForwardEuler) which is an explicit method. It is first order accurate in time and the maximal timestep size is limited by the CFL condition. Therfore, the maximal time increment is much smaller compared to the previous case which leads to much longer simulation times.
[7]:
from evoxels.timesteppers import ForwardEuler
vf.add_field("c4", noise)
dt = 0.005
solver = TimeDependentSolver(
vf, 'c4', 'torch', device='cuda',
problem_cls = CahnHilliard,
timestepper_cls = ForwardEuler
)
solver.solve(
time_increment=dt, frames=10, max_iters=int(final_time/dt),
problem_kwargs={"eps": 3.0, "D": 1.0},
jit=True
)
Wall time: 820.135 s after 200000 iterations (0.0041 s/iter)
GPU-RAM (nvidia-smi) current: 413 MB (413.0 MB max)
GPU-RAM (torch) current: 48.83 MB (132.15 MB max, 182.00 MB reserved)
Custom solver kernel
Instead of discretising the spatial gradients in the Cahn-Hilliard equation based on second order finite differences, we can go to Fourier space. This can be realised by writing your own custom solver kernel
[8]:
import torch
import torch.fft as fft
vf.add_field("c", noise)
dt = 1
eps = 3.0
D = 1.0
A = 0.25
# Define wavenumbers
fft_axes = tuple(2 * torch.pi * fft.fftfreq(points, step)
for points, step in zip(vf.shape, vf.spacing))
kx, ky, kz = torch.meshgrid(*fft_axes, indexing='ij')
k_squared = kx**2 + ky**2 + kz**2
# Define stepfunction
def custom_step_function(t, c):
c = torch.clip(c, 0, 1)
mu_hom = 18/eps * c * (1-c) * (1-2*c)
c_hat = fft.fftn(c)
mobility = D * c * (1-c)
mu_hat = fft.fftn(mu_hom) + 2 * eps * k_squared * c_hat
flux_x = mobility * torch.real(fft.ifftn(1j * kx * mu_hat))
flux_y = mobility * torch.real(fft.ifftn(1j * ky * mu_hat))
flux_z = mobility * torch.real(fft.ifftn(1j * kz * mu_hat))
flux_div = 1j * (kx*fft.fftn(flux_x) + ky*fft.fftn(flux_y) + kz*fft.fftn(flux_z))
c_hat += dt*flux_div / (1 + 2*eps*dt*D*k_squared**2*A)
return torch.real(fft.ifftn(c_hat))
# Solver setup and solve
solver = TimeDependentSolver(
vf, 'c', 'torch', device='cuda',
step_fn = custom_step_function
)
solver.solve(
time_increment=dt, frames=10, max_iters=int(final_time/dt),
jit=False, verbose='plot', plot_bounds=(0,1)
)
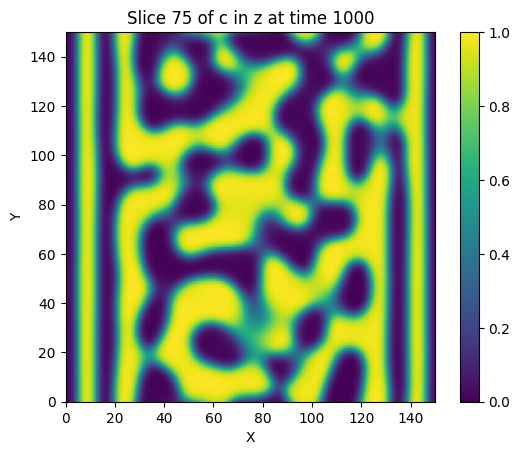
Wall time: 39.6549 s after 1000 iterations (0.0397 s/iter)
GPU-RAM (nvidia-smi) current: 621 MB (621.0 MB max)
GPU-RAM (torch) current: 74.83 MB (334.08 MB max, 390.00 MB reserved)
Note: Complex operators cannot be jit compiled! Torch will promt an error when jit=True.
Callable chemical potential
ODE classes can be defined with callable input arguments. In case of the Cahn-Hilliard solver, the default homogeneous chemical potential is \(g(\phi)=\frac{18}{\epsilon}\phi(1-\phi)(1-2\phi)\) which is derived from the double-well potential in the energy functional as discussed in the introduction. Alternatively, we can define \(g(\phi)\) based on a regular solution free energy (see Cahn & Hilliard) as \(g(\phi)=\ln(\phi)-\ln(1-\phi) + \Omega(1-2\phi)\)
Note that one input argument for the callable function must be lib as soon as backend specific functions such as torch.log or jax.numpy.sin are used. The solver will replace lib with the backend-specific library.
[9]:
def regular_solution_mu(c, lib):
return lib.log(c) - lib.log(1-c) + 3.0*(1-2*c)
[10]:
vf.add_field("c", noise)
dt = 1
steps = int(final_time/dt)
evo.run_cahn_hilliard_solver(
vf, 'c', 'torch', jit=True, device='cuda',
time_increment=dt, frames=10, max_iters=steps,
eps = 3.0, diffusivity = 1.0, mu_hom = regular_solution_mu,
verbose='plot', vtk_out=False, plot_bounds=(0,1)
)
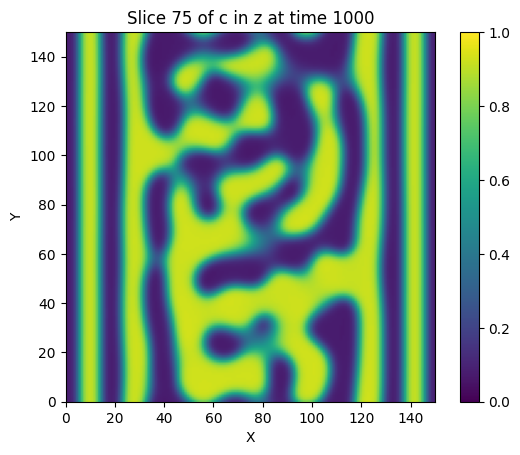
Wall time: 20.1378 s after 1000 iterations (0.0201 s/iter)
GPU-RAM (nvidia-smi) current: 621 MB (621.0 MB max)
GPU-RAM (torch) current: 60.75 MB (156.28 MB max, 390.00 MB reserved)
Float precision and wall time
The float precision plays an immense roll for the runtime on a GPU as only single precision is naturally supported. The torch/jax backend inherits the float precision from the VoxelFields object. The default value is float32 (single precision).
[11]:
vf.precision
[11]:
'float32'
[12]:
vf.add_field("c", noise)
evo.run_cahn_hilliard_solver(
vf, 'c', 'torch', jit=False, device='cuda',
time_increment=dt, frames=10, max_iters=steps,
eps = 3.0, diffusivity = 1.0
)
Wall time: 18.329 s after 1000 iterations (0.0183 s/iter)
GPU-RAM (nvidia-smi) current: 621 MB (621.0 MB max)
GPU-RAM (torch) current: 60.76 MB (168.34 MB max, 390.00 MB reserved)
We can intentionally set the float precision to double which might be necessary for small spacings dx but this can mostly be circumvented by proper non-dimensionalisation!
[13]:
vf.precision = 'float64'
…and perform the same simulation again
[14]:
vf.add_field("c", noise)
evo.run_cahn_hilliard_solver(
vf, 'c', 'torch', jit=False, device='cuda',
time_increment=dt, frames=10, max_iters=steps,
eps = 3.0, diffusivity = 1.0
)
Wall time: 41.3098 s after 1000 iterations (0.0413 s/iter)
GPU-RAM (nvidia-smi) current: 793 MB (793.0 MB max)
GPU-RAM (torch) current: 93.53 MB (305.41 MB max, 558.00 MB reserved)